June 20, 2024
This post was originally a small research paper I wrote for a university course exploring distributed approaches to machine learning training. The work investigates whether distributing the forward propagation phase of Multilayer Perceptron training across multiple machines could be practical. You can find the implementation and code for this project on GitHub.
Abstract
In today's world, machine learning has become a feasible solution for problems which require algorithmic evaluation [5]. One of the significant factors of improving model accuracy in machine learning is extending the training data [6] which results in the training step of building models to be more computationally dependent. Especially due to the widespread adoption of large language models (LLM), the requirement for more parameters increased [7] which in turn led to an unprecedented demand for computational power. Most of the companies that offer machine learning solutions either have access to systems with large computational capabilities or have means to leverage such computation elsewhere such as Google, [8] Open AI [9] and Mixtral [10]. This puts an unexpected barrier of entry to building machine learning solutions at scale. All of this establishes a need for a distributed approach to machine learning. This report will explore a distributed approach for the forward propagation phase of Multilayer Perceptron training, demonstrating how computation can be parallelized across multiple machines as it is a commonly used method in Machine Learning [3] [4].
Keywords: Multilayer Perceptron, Large Language Models, Forward Propagation, Backward Propagation, Machine Learning, Neurons and Layers.
1. Introduction
The training step of Multilayer Perceptron can be described in three parts. These parts are Forward Propagation, Backpropagation and Update of Parameters. [2] Multilayer Perceptron's model skeleton consists of a sequentially connected group of neurons called layers [1] [3].
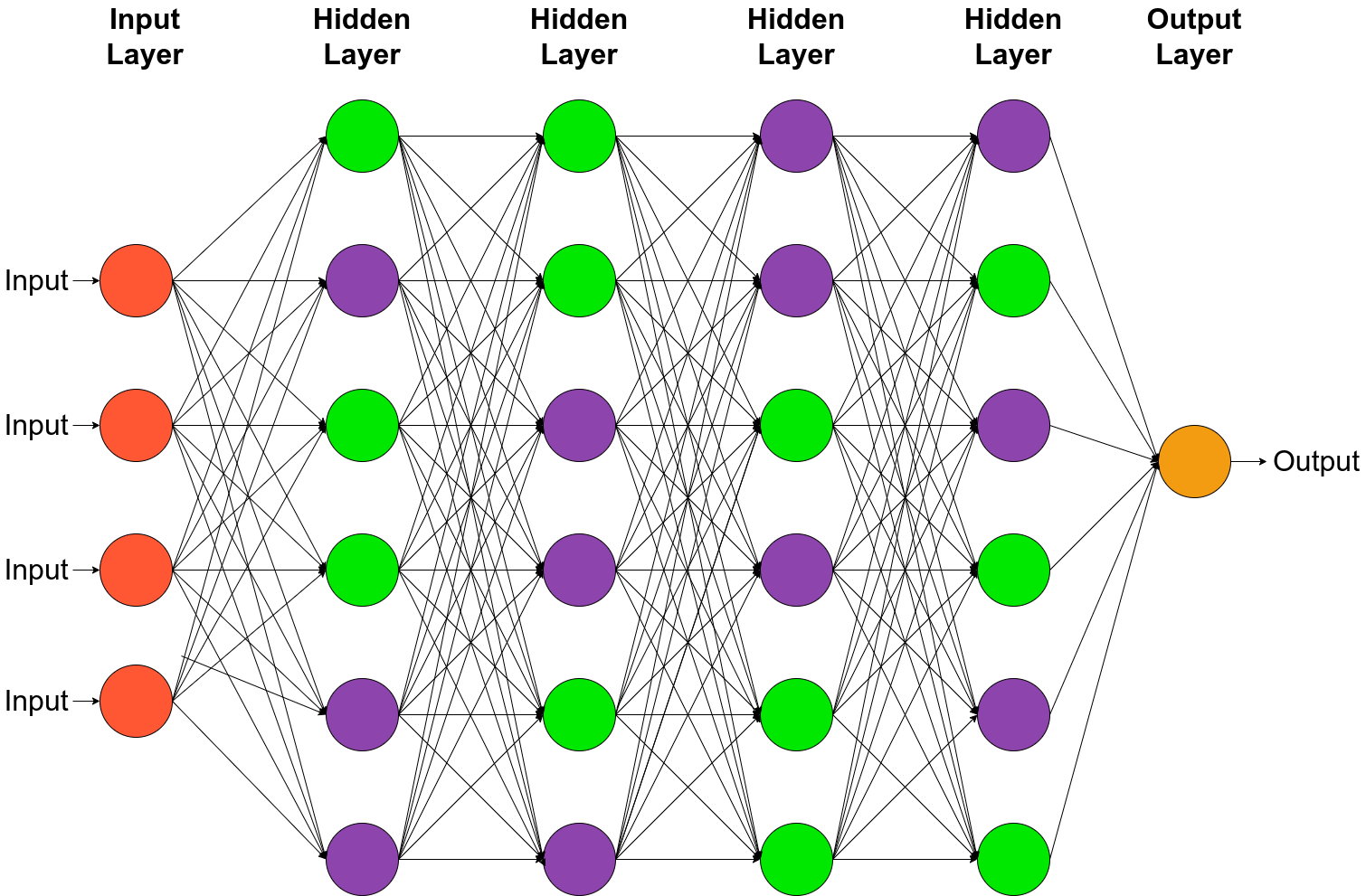
In the context of the Forward Propagation, neurons represent a set of mathematical operations applied to the input of said neuron [2]. After the Forward Propagation is completed, the Backpropagation is applied on the neurons to calculate new values for the parameters of the said neuron to better approximate results [1] [2].
2. Proposal
The Forward Propagation or action of passing values through the neurons is only dependent on previous neurons and is independent of neighbouring neurons in the same layer [2] [4]. This means that the actions of these neighbouring neurons in a layer can be distributed among peers in a group of computation systems. This distribution preserves the sequential aspect of the forward propagation while dividing the cost to compute between different peers instead of a single system. These computing systems can range from individual CPU cores to multiple machines interconnected within the same network. The example application described in this report utilizes a network of machines as the group of computing systems.
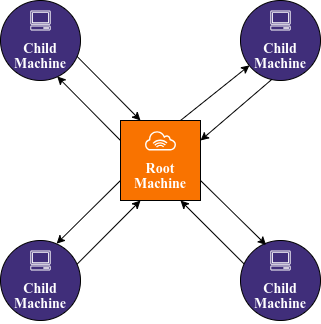
At each layer of the forward propagation process, the root machine divides the neurons in the current layer to each child (client) machine, sends them the necessary information to process the neuron operations, gathers the outputs back from the child machines and proceeds to the next layer.
Main bottleneck in this procedure is the speed of the information pipeline between the root machine and each child machine. Only the necessary information should be transferred between machines to lower the cost of transfer as much as possible. In the end a specialized information packet is devised.

Operations are grouped as Information packets. The group ID is essential for the root machine to identify each group when it receives the results.

The child machine only needs to know inputs and parameters per neuron operation. Using all this information the child machine can compute the forward propagation and can send the outputs back utilizing the same information packet schema with the operation type being zero which is reserved for the results. Rest of the operation types refer to the activation function used by the neuron.
3. Overview
Example software was developed to gather more information about the reliability and performance of the distributed approach. This software trains a simple Multilayer Perceptron model with different configurations necessary for this report.
Initially, the distributed approach was slower as it was expected when considering the time required to train the model while the parameter count was increased.
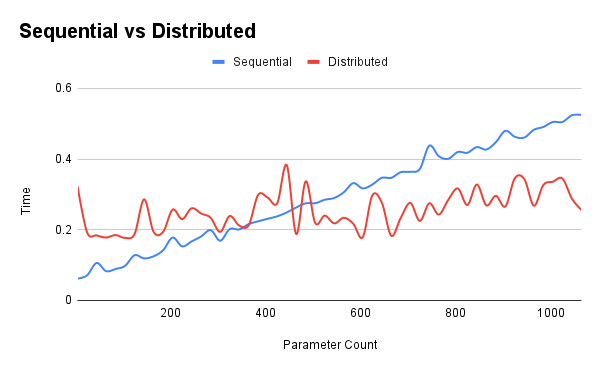
After a certain parameter count, the duration of the non-distributed approach becomes slower than the distributed. As the cost of computation per layer increases (parameter count), the time it takes for multiple machines to work together on forward propagation compared to a single machine gets faster. While the time trade off of sending the information between machines becomes negligible.
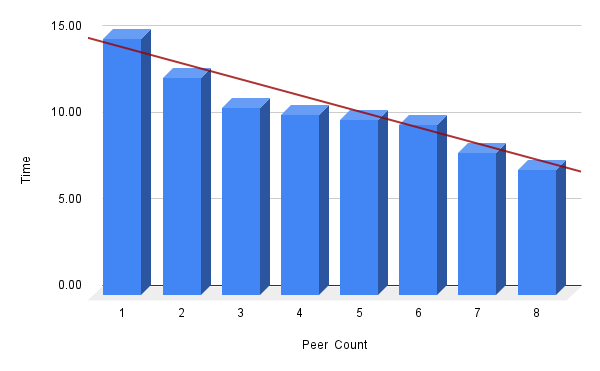
Amount of child machines is also an important factor for training time. Balancing the trade-off between training on a single machine and distributing the workload across a network of machines is crucial to achieve improvement in the overall computation time.
4. Conclusion
It is apparent that the distributed approach divides the cost of computation when training larger models. This division lets multiple systems share the workflow of the training task. In turn, it opens up the possibility of new ways to train and to structure a Machine Learning project. A single entity doesn't have to bear the burden of computational costs. More collaborative approaches to planning and structuring of Model Creation can be attained. This could loosen the connection between machine learning and substantial funding requirements, making it more accessible for a broader range of people having means to develop their own machine learning models.
This project implements distribution only for the forward propagation phase of training, with backpropagation and weight updates remaining sequential. It is possible to implement and design distributed approaches to parts such as backward propagation as well. When building an example for this report it was also observed that utilizing a more strictly typed programming language can help the process as the networking in combination with the machine learning extends the need for accuracy.
5. References
- Popescu, Marius-Constantin & Balas, Valentina & Perescu-Popescu, Liliana & Mastorakis, Nikos. Multilayer perceptron and neural networks. WSEAS Transactions on Circuits and Systems. 2009.
- Chen J-F, Do QH, Hsieh H-N. Training Artificial Neural Networks by a Hybrid PSO-CS Algorithm. Algorithms. 2015.
- Kit Yan Chan, Bilal Abu-Salih, Raneem Qaddoura, Ala' M. Al-Zoubi, Vasile Palade, Duc-Son Pham, Javier Del Ser, Khan Muhammad. Deep neural networks in the cloud: Review, applications, challenges and research directions. Neurocomputing. Volume 545. 2023.
- S. Park, S. Lek. Chapter 7 - Artificial Neural Networks: Multilayer Perceptron for Ecological Modelling, Developments in Environmental Modelling. Elsevier. Volume 28. 2016.
- Sarker, I.H. Machine Learning: Algorithms, Real-World Applications and Research Directions. SN COMPUT. SCI. 2, 160 (2021).
- V. K and G. Dayalan, Framework for Improving the Accuracy of the Machine Learning Model in Predicting Future Values. 2023 IEEE 8th International Conference for Convergence in Technology (I2CT), Lonavla, India, 2023, pp. 1-8.
- Naveed, Humza, et al. A comprehensive overview of large language models. arXiv preprint arXiv:2307.06435 (2023).
- Gemini Google DeepMind. Retrieved from https://deepmind.google/technologies/gemini/
- Quickstart - Get started using GPT-35-Turbo and GPT-4 with Azure OpenAI Service. Microsoft Learn. Retrieved from https://learn.microsoft.com/en-us/azure/ai-services/openai/chatgpt-quickstart
- E. Boyd, "Introducing Mistral-Large on Azure in partnership with Mistral AI," Microsoft Azure Blog, Feb. 26, 2024.